Spouštět něco přes nějakej virtuál je zpomalování samo o sobě. Mě se pod Win osvědčuje zkoušet kdyžtak portable verze. Mám nyní stabilní verzi 6.2.8.2 x64 na Win10prof a na tu si nemohu nijak moc stěžovat, ba naopak ji považuji za hodně povedenou.
Zde je testovací soubor https://uloz.to/file/WuW1B68nGG6M/sloup … ku-kl2-ods , jen zkopíruje do druhého listu řádky do sloupců pomocí getTransferable. Při vykreslovaném okně na 6.2.8.2 za 9 sekund, na portable 6.0 za 16s; při schovaném okně obě verze za 4s. Skutečně mi nepřijde, že by zrovna makra běhala nějak pomaleji na 6.2 než na předchozích verzích a to dělám makra asi 4 roky a samozřejmě jsem ten svůj makro-projekt dělal i na těch předchozích verzích.
Ale setkal jsem se s tím, že se zpomalil celý Calc, kdy se třeba kliklo na nějaké tlačítko a spustilo to nějakou šílenou smyčku, ve které stoupl výkon procesoru na 100% (zjištěno přes Ctrl+Alt+Del) a pak nešlo dělat téměř nic. Verzi si již nepamatuji, dělalo to ve více verzích, ale bylo to po pár měsících opraveno.
Spíše nepovedená pro Basic editor je verze 6.3.4, byla v ní po asi čtvrt roce opravena nahlášená chyba kdy při označení kódu zmizelo barevné zvýrazňování, jenže celý Basic editor se zpomalil, v něčem i značně. Pro 6.4 nevím, na to nemám náladu ji zkoušet. Připomíná mi to ale sérii 5.x, kdy 5.0 jela oproti 4.něco v pohodě (alespoň v tom co jsem dělal), 5.1 a 5.2 též, ale od 5.3 už se to pro mé potřeby nedalo, přibyly nějaké nové fce a starý laptop už to nestíhal. Asi až nějaká 5.6 byla zase v pohodě a dalo se na ní dělat i na stařečkovi.
Když jede pomalu Basic editor, tak je možné že pojedou pomaleji i makra, nebo třeba jen některá s nějakými funkcemi. To nedokáži říci, tak velký a zainteresovaný programátor nejsem.
Ale v 6.2.8.2 se mi třeba stává, že když mám spuštěno více oken Libre (byť tedy hlavně Writer) a do toho ve FontForge dělám font a každou chvíli jej přeinstalovávám abych viděl jak se mi co zobrazuje v Libre, tak někdy začne hučet větrák a v Ctrl+Alt+Del zjistím, že Libre žere procesor poněkud víc než před pár minutami, a žere ho pořád a to i když přerstanu cokoliv dělat a tedy nic nedělám a žádné makro neběží a jen čučím na tu křivku výkonu v Ctrl+Alt+Del. Vypnu Libre, spustím znova se soubory které jsem měl spuštěné a procesor je v pohodě, žádný zvýšený výkon a větrák točit přestane. Reprodukovat tu chybu neumím, prostě někdy to jede při tom re-fontování v pohodě, ale někdy se prostě rozeběhne větrák a když hučí pár minut, tak vím, že musím Libre restartovat, páč prostě nějak začalo užírat procesor.
Jinak 6.2.8.2 a 6.3+ mají oproti předchozím verzím zrychlené načítání souborů a to je sakra pěkná vlastnost.
---------------------------------
Zkusím vám trochu nastínit hlubší programování byť nikterak velký ajťák nejsem a doufám, že má odpověď a příklady budou více japné než nejapné! :-).
Odpovědí pro příčinu bude nejspíš programátorsky řečeno: objekty+vyjímky a MNOŽSTVÍ toho všeho :-). Jestli vám říká něco pojem objektově orientované programování a umíte si představit strukturu s několika desítkami či stovkami tisíc objektů které jsou v sobě všelijak vloženy třeba v několika desítkách úrovních, tak pak si jistě lehce představíte, že někde v třicáté osmé úrovni nějakého desetitisíctého objektu uděláte třeba nějakou změnu a až třeba i po pár měsících bádání zjistíte, že tahle změna neblaze ovlivňuje něco v padesáté úrovni objektu 183 tisíc. A že jste za tu dobu perně prozkoumal snad pět tisíc objektů než jste k tomu došel.
Na vytváření Libre se podílelo/podílí nejspíše několik stovek (ale možná i tisíců) programátorů a všichni to dělají nejspíše ryze dobrovolně. Tak obsáhlý program s tolika možnostmi není možné naprogramovat bez chyb, stejně jako není možné pro všechny varianty které se v programování vyskytnou udělat jednoznačné výsledky -> něco je vhodné tak, něco onak; pro něco je možné více variant a všechny mohou být více vhodné než nevhodné; pro něco naopak mohou být všechny varianty nakonec nevhodnější než vhodné ale již je to potřeba tak použít, aby se tím nerozsypalo něco předchozího. A každý programátor prostě zvolí něco jiného. No a někdy něco díky ohromné provázanosti objektů ovlivní i něco, co by třeba nikdo nečekal. Pak by se mělo přijít na to kde to co ovlivnilo, jenže ve struktuře která má všelijak provázáno třeba přes milión objektů to fakt nemusí být pro člověka nikterak jednoduché. No a pak když se to opraví tak se ale snadno stane, že oprava opět ovlivní něco jiného, zcela nečekaně.
Ono je také něco jiného něco sám naprogramovat, a něco úplně jiného vyznat se alespoň zčásti v tom, co naprogramoval někdo jiný. Sto programátorů nejspíše vyplodí sto všelijak odlišných řešení - někdy vzájemně lehce odlišných, někdy těžce, někdy třeba i neuvěřitelně odlišných. Sice se lze na něčem dohodnout že se to bude psát a strukturovat tak či onak, jenže je to spíše jak s lidskými jazyky -> zkusíte se dohodnout primitivní anglinou, avšak něco mnohem lépe vyjádříte češtinou, něco třeba arabštinou, něco jiného ruštinou, jiné čínštinou, něco sanskrtem, něco nějak inidiánsky -> a ta anglina vám tam v tom bude díky své primitivnosti zato však egoičnosti spíše pro naštvání, než že by to reálně pomáhalo k bezchybnosti. No a s těmi ostatními jazyky co něco umožňují popsat mnohem mnohem lépe, tak ty se nenaučíte nebo se je na potřebné úrovni nenaučí ostatní kteří se na tom podílí, pročež vám nezbývá než to zase zprimitivnit do té angliny :-).
Navíc jak je to dobrovolné, tak ne vždy na něco musí mít někdo čas, mezitím někdo jiný mohl udělat něco co to též ovlivnilo a již je v tom tedy víc věcí apod. V tak obsáhlém množství tak provázaných objektů se nikdo z lidí pořádně nevyzná a nedokáže to na 100% dělat již jen dobře.
Ve firmě to může vypadat tak, že přijde šéf a nařídí -> tohle je problém, echt cálujícího zákazníka to fakt dožralo, opravte to! A víte jak to pak nejspíše dopadne? Mají tam ten samý problém, že v obsáhlé objektové struktuře se nikdo z nich nevyzná, ti nejlepší by to možná zvládli za pár desítek let kdyby se v tom již nic neměnilo a nemuseli se ničím jiným zabývat, ale ten čas a možnou ignoraci všeho ostatního nemají. Takže pak namísto nalezení chyby a opravení zaprogramují vyjímky, kdy se při "chybě" spustí něco dalšího, co to má provést lépe. Chyba samotná zůstane a když ji bude vyvolávat i něco ještě dalšího, tak se tam naflákají další vyjímky. A máte čím dál větší bordel.
Sám tak obsáhlý projekt jako je Libre v podstatě nenaprogramujete (skutečně zapomeňte na zhovadilosti typu že jeden člověk naprogramuje matrix pro většinu populace), a čím víc lidí se na tom bude podílet, tím víc různých řešení bude zkombinováno, samozřejmě se všemi možnými specifiky i chybami. A čím to bude umět víc funkcí, tím víc to bude nepřehledné a náročné na nějaké opravy a změny. To je prostě programování. Někdo něco naprogramuje, pak se objeví chyba, musí se najít někdo kdo objeví kde chyba je, pak jestli ji bude umět opravit, a pak při již obsáhlé struktuře spíše doufat, že to nějak moc nerozhodí něco jiného :-).
Ono prostě kolikrát ani přesně nevíte jak něco vlastně naprogramovat a tak různě zkoušíte, až to zbastlíte tak, že to začne dělat to co si představujete. Ono to ve skutečnosti dělá i něco co třeba nechcete, ale otestoval jste to jen na to co chcete a nikoliv na to co byste nechtěl. Testovat na všechny možné nechtěné stavy je nemožné, takže se - když už se testuje - testuje nejspíše jen na to co to má dělat a nikoliv na to co to kdy kde nemá dělat. Pak se k tomu za čas vrátíte a třeba to chcete nějak vylepšit, páč vás napadla třeba nějaká optimalizace. Tak to zlepšíte. Jenže mezitím už to někdo využil k něčemu dalšímu a ta optimalizace nerozhodí to další, ale až nějaké to další další, které vyšlo z toho předchozího dalšího ale i z kusu něčeho jiného, což bylo taky třeba naprogramováno zčásti jako jasné a zčásti jako experimentální. A do toho se motá něco jiného taky od někoho jiného a ještě něco dalšího z něčeho jiného předchozího z čehož vychází něco dalšího spojující se zase v něčem dalším i jiném předchozím. Že už se v tom mém popisu nevyznáte? Já téměř také ne, a to je tam "popsáno" snad jen šest či sedm částí od několika autorů :-). No a představte si třeba deseti nebo stotisíce či milióny částí od několika stovek či tisíců programátorů. Jde vám to si to představit? Mě teda už nějak ne :-).
Profi programátor nejsem, ale pokud sám nenaprogramujete něco obsáhlejšího tak si složitosti se stovkami tisíc a více objektů asi nedokážete jen tak představit. Nevím k čemu bych vám to ještě zkusil připodobnit, zkusím další příklad spíše k zákeřnosti některých chyb a nikoliv zamotanosti programátorských řešení. Třeba v nějaké knihovně v okresním městě by vám čtenář nahlásil, že v nějaké knize našel špatné slovo a namísto "počítač" tam bylo napsáno třeba "poxítač" - a pomohl by vám natolik, že by vám sdělil, že byla mnohem hubenější než bible, že měla asi jen 2cm tloušťky, a že měla dokonce takové tmavší desky. A na vás by bylo, abyste tam někde tu neznámou knihu našel a nahlásil vydavateli stránku a odstavec se špatným slovem :-). To by byla jedna zákeřná chyba. Objevil byste i jiné. A pak byste zjistil, že nejlepší by bylo nakonec předělat font v knihách v celém jednom oddělení :-). Po několika letech tištění těch knih. Prý s novým fontem by to celé bylo lepší. Tak byste se do toho pustil. A za pár let po dokončení re-tisku byste zjistil, že ten původní font v něčem co jste si nevšiml byl lepší než ten nový, ve kterém jste také naflákal nějaké chyby. Takže máte chyby jak v tom starém tak v tom novém. A ste o pár let starší. A čtenáři pořád chtějí další a další knihy. A nalézají další a další chyby a chtějí další a další "zlepšení" :-). A vy na to máte nějaké staré fonty s chybami a nové fonty s chybami. A ani nevíte kde všude se vám to motá a už vůbec netušíte, kde všude se vám to bude motat dál když v tom budete pokračovat. Ale že se to v případě pokračování zamotá, o tom již nepochybujete.
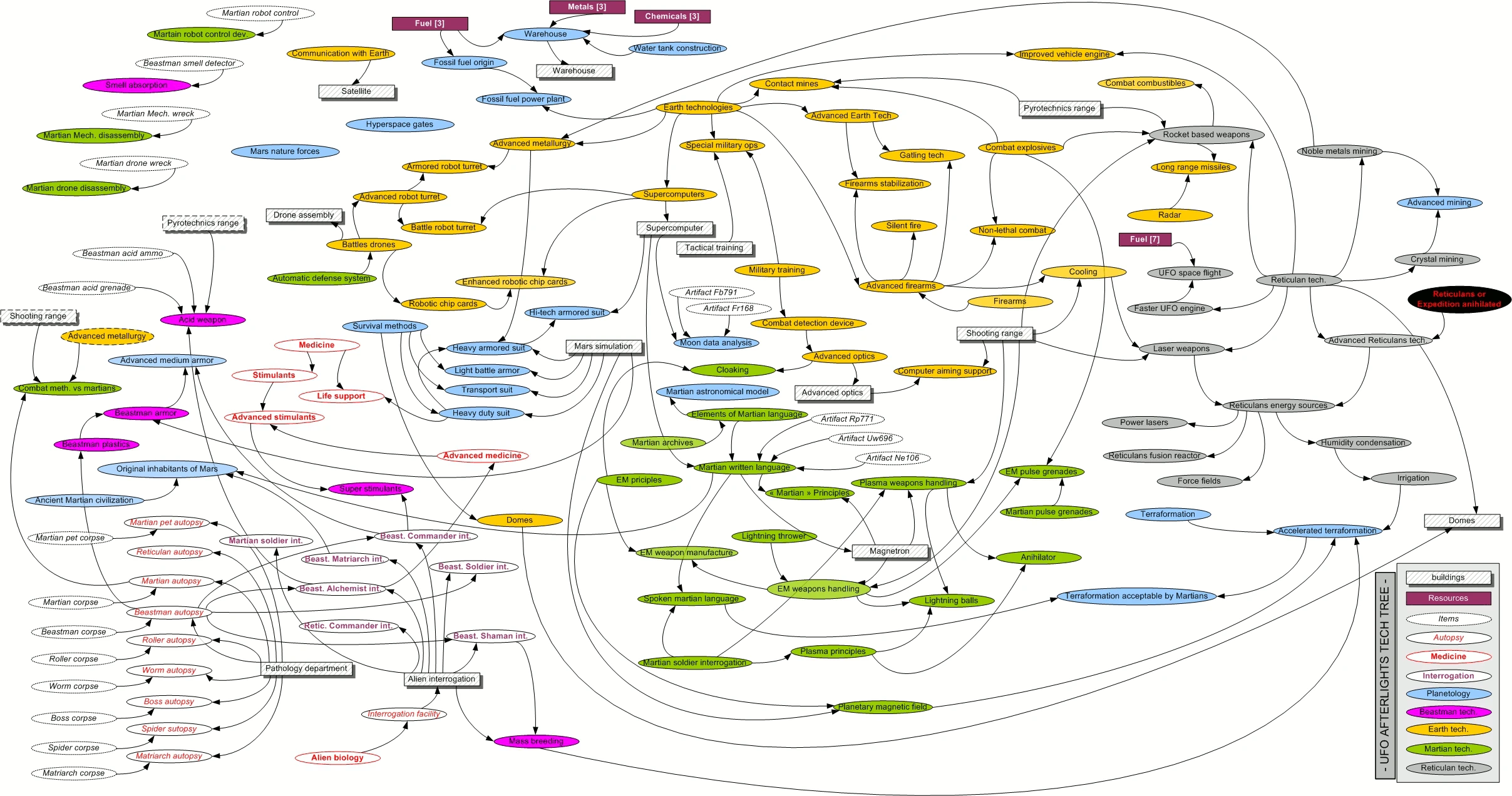
Ještě vás možná napadne, že než někdo něco naprogramuje, tak by si měl pořádně promyslet návrh jak co bude provázané a jak bude co ovlivňovat něco dalšího, nebo si ještě lépe udělat nějaké pořádné schéma (plán) podle kterého se bude postupovat. Před lety jsem hrál jednu ufo hru - pokud neznáte ty ufo hry, tak jde v podstatě jen o to, že svými panďuláčky máte vystřílet ufounské panďuláčky, přičemž tam je nějaký výzkum kde vám s postupujícimi zkušenostmi a bádáním je umožňováno vylepšovat si třeba zbraně. Zde je obrázek toho schématu vědeckého vývoje v té hře https://vignette.wikia.nocookie.net/ufo … 0923160939 . No a asi se nebudu moc mýlit, že v tak obsáhlém programu jakým je Libre by takovýhle schémat bylo klidně i desítky a možná i stovky tisíc, přičemž ten uvedený ufounský by byl jeden z těch pidi-malých a jó-přehledných :-).
Zajisté mé jakési "vysvětlení" není pro vás nic potěšujícího, ale jak to dělat lépe, to skutečně nikdo z lidí zatím asi nevymyslel. Samotného mě ty různé opět-se-objevující chyby v Libre někdy dost znechucují či deprimují a to rozhodně nejsem sám. I sami různí vývojáři si nad tím někdy zoufají či z toho odpadají. Ale k dokonalosti to programování zatím asi nikdo nevymyslel.
O tom že nějací týpci dosáhli dokonalosti občas mluví něco tzv. budhisté, ale ti týpci o tom nedokonalém poté co prý spatřili jak vznikají i zanikají snad i celé vesmíry prý akorát řekli: "vše je pomíjivé" :-). Takže zajisté i Libre pomine, tutově s chybami, na mohutné rozsvícení po kterém to vše bude již jen OK, to Libre ani jiný softvér a ani samotné programování asi nikdy nedotáhne :-). Pro někoho možná bohužel, možná však ale i Bohu dík, aspoň je čas i na jiné věci než jen pořád na keply.
{kind=link}